2.1 Introduction
The theory of Computational Law begins with the concept of a dataset. A dataset is a collection of facts about some aspect of the world. Datasets can be used by themselves to encode information. They can also be used in combination with logic programs to form more complex information systems, as we shall see in the coming chapters.
We begin this chapter by talking about conceptualizing the world. We then introduce a formal language for encoding information about our conceptualization in the form of datasets. We provide some examples of datasets encoded within this language. And, finally, we discuss the issues involved in reconceptualizing an application area and encoding those different conceptualizations as datasets with different vocabularies.
2.2 Conceptualization
When we think about the world, we usually think in terms of objects and relationships among these objects. Objects include things like people and offices and buildings. Relationships include things like parenthood, friendship, office assignments, office locations, and so forth.
One way to represent such information is in the form of graphs. As an example, consider the graph shown below. The nodes here represent objects, and the arcs represent relationships among these objects.
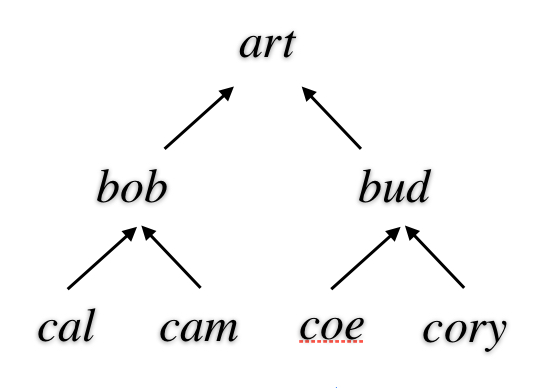
Alternatively, we can represent such information in the form of tables. For example, we can encode the information the information in the preceding graph as a table like the one shown below.
| parent |
|---|
| art | bob |
| art | bea |
| bob | cal |
| bob | cam |
| bea | coe |
| bea | cory |
Another possibility is to encode individual relationships as sentences in a formal language. For example, we can represent our kinship information as shown below. Here, each fact takes the form of a sentence consisting of name for the relationship and the names of the entities involved.
| parent(art,bob) |
| parent(art,bea) |
| parent(bob,cal) |
| parent(bob,cam) |
| parent(bea,coe) |
| parent(bea,cory) |
While graphs and tables are intuitively appealing, a sentential representation is more useful for our purposes. So, in what follows we represent facts as sentences, and we represent different states of the world as different sets of such sentences.
A final note before we leave this discussion of conceptualization. In what follows, we use the words relation and relationship interchangeably. From a mathematical point of view, this is not exactly correct, as there is a subtle difference between the two notions. However, for our purposes, the difference is unimportant, and it is often easier to say relation than relationship.
2.3 Datasets
A dataset is a collection of simple facts that characterize the state of an application area. Facts in a dataset are assumed to be true; facts that are not included in the dataset are assumed to be false. Different datasets characterize different states.
Constants are strings of lower case letters, digits, underscores, and periods or strings of arbitrary ASCII characters enclosed by double quotes. For reasons described in the next chapter, we prohibit strings containing upper case letters except within double quotes. Examples of constants include a, b, comp225, 123, 3.14159, barack_obama, and "Mind your p's and q's!". Non-examples include Art, p&q, the-house-that-jack-built. The first contains an upper case letter; the second contains an ampersand; and the third contains hyphens. A vocabulary is a collection of constants.
In what follows, we distinguish two types of constants. Symbols are intended to represent objects in the world, and predicates are intended to represent relationships on objects.
Each predicate has an associated arity, i.e. the number of arguments allowed in any expression involving the predicate. Unary predicates are those that take one argument; binary predicates take two arguments; ternary predicates take three arguments. Beyond that, we often say that predicates are n-ary. Note that it is possible to have a predicate with no arguments, representing a condition that is simply true or false.
A datum / factoid / fact is an expression formed from an n-ary predicate and n symbols enclosed in parentheses and separated by commas. For example, if r is a binary predicate and a and b are symbols, then r(a,b) is a datum.
The Herbrand base for a vocabulary is the set of all factoids that can be formed from the constants in the vocabulary. For example, for a vocabulary with just two symbols a and b and the single binary predicate r, the the Herbrand base for this language is shown below.
{r(a,a), r(a,b), r(b,a), r(b,b)}
Finally, we define a dataset to be any subset of the Herbrand base, i.e. an arbitrary set of facts that can be formed from the vocabulary of a database. Intuitively, we can think of the data in a dataset as the facts that we believe to be true; data that are not in the dataset are assumed to be false.
2.4 Example - Sorority World
Consider the interpersonal relations of a small sorority. There are just four members - Abby, Bess, Cody, and Dana. Some of the girls like each other, but some do not.
Figure 1 shows one set of possibilities. The checkmark in the first row here means that Abby likes Cody, while the absence of a checkmark means that Abby does not like the other girls (including herself). Bess likes Cody too. Cody likes everyone but herself. And Dana also likes the popular Cody.
| |
Abby |
Bess |
Cody |
Dana |
| Abby |
|
|
 |
|
| Bess |
|
|
|
|
| Cody |
|
|
|
|
| Dana |
|
|
|
|
|
| Figure 1 - One state of Sorority World |
In order to encode this information as a dataset, we adopt a vocabulary with four symbols (abby, bess, cody, dana) and one binary predicate (likes). Using this vocabulary, we can encode the information in Figure 1 by writing the dataset shown below.
| likes(abby,cody) |
| likes(bess,cody) |
| likes(cody,abby) |
| likes(cody,bess) |
| likes(cody,dana) |
| likes(dana,cody) |
Note that the likes relation has no inherent restrictions. It is possible for one person to like a second without the second person liking the first. It is possible for a person to like just one other person or many people or nobody. It is possible that everyone likes everyone or no one likes anyone.
Even for a small world like this one, there are quite a few possible ways the world could be. Given four girls, there are sixteen possible instances of the likes relation - likes(abby,abby), likes(abby,bess), likes(abby,cody), likes(abby,dana), likes(bess,abby), and so forth. Each of these sixteen can be either true or false. There are 216 (i.e. 65,536) possible combinations of these true-false possibilities; and so there are 216 possible states of this world and, therefore, 216 possible datasets.
2.5 Example - Kinship
As another example, consider a small dataset about kinship. The terms in this case once again represent people. The predicates name properties of these people and their relationships with each other.
In our example, we use the binary predicate parent to specify that one person is a parent of another. The sentences below constitute a dataset describing six instances of the parent relation. The person named art is a parent of the person named bob and the person named bea; bob is the parent of cal and cam; and bea is the parent of coe and cory.
| parent(art,bob) |
| parent(art,bea) |
| parent(bob,cal) |
| parent(bob,cam) |
| parent(bea,coe) |
| parent(bea,cory) |
The adult relation is a unary relation, i.e. a simple property of a person, not a relationship with other people. In the dataset below, everyone is an adult except for Art's grandchildren.
| adult(art) |
| adult(bob) |
| adult(bea) |
We can express gender with two unary predicates male and female. The following data expresses the genders of all of the people in our dataset. Note that, in principle, we need only one relation here, since one gender is the complement of the other. However, representing both allows us to enumerate instances of both gender equally efficiently, which can be useful in certain applications.
| male(art) | | female(bea) |
| male(bob) | | female(coe) |
| male(cal) | | female(cory) |
| male(cam) | | |
As an example of a ternary relation, consider the data shown below. Here, we use prefers to represent the fact that the first person likes the second person more than the third person. For example, the first sentence says that Art prefers bea to bob; the second sentence says that bob prefers cal to cam.
| prefers(art,bea,bob) |
| prefers(bob,cal,cam) |
Note that the order of arguments in such sentences is arbitrary. Given the meaning of the prefers relation in our example, the first argument denotes the subject, the second argument is the person who is preferred, and the third argument denotes the person who is less preferred. We could equally well have interpreted the arguments in other orders. The important thing is consistency - once we choose to interpret the arguments in one way, we must stick to that interpretation everywhere.
One noteworthy difference difference between Sorority World and Kinship is that there is just one relation in the former (i.e. the likes relation), whereas there are multiple relations in the latter (three unary predicates, one binary predicate, and one ternary predicate).
A more subtle and interesting difference is that the relations in Kinship are constrained in various ways while the likes relation in Sorority World is not. It is possible for any person in Sorority World to like any other person; all combinations of likes and dislikes are possible. By contrast, in Kinship there are constraints that limit the number of possible states. For example, it is not possible for a person to be his own parent, and it is not possible for a person to be both male and female.
2.6 Example - Blocks World
The Blocks World is a popular application area for illustrating ideas in the field of Artificial Intelligence. A typical Blocks World scene is shown in Figure 2.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
| Figure 2 - One state of Blocks World. |
Most people looking at this figure interpret it as a configuration of five toy blocks. Some people conceptualize the table on which the blocks are resting as an object as well; but, for simplicity, we ignore it here.
In order to describe this scene, we adopt a vocabulary with five symbols (a, b, c, d, e), with one symbol for each of the five blocks in the scene. The intent here is for each of these symbols to represent the block marked with the corresponding capital letter in the scene.
In a spatial conceptualization of the Blocks World, there are numerous meaningful relations. For example, it makes sense to talk about the relation that holds between two blocks if and only if one is resting on the other. In what follows, we use the predicate on to refer to this relation. We might also talk about the relation that holds between two blocks if and only if one is anywhere above the other, i.e. the first is resting on the second or is resting on a block that is resting on the second, and so forth. In what follows, we use the predicate above to talk about this relation. There is the relation that holds of three blocks that are stacked one on top of the other. We use the predicate stack as a name for this relation. We use the predicate clear to denote the relation that holds of a block if and only if there is no block on top of it. We use the predicate table to denote the relation that holds of a block if and only if that block is resting on the table.
The arities of these predicates are determined by their intended use. Since on is intended to denote a relation between two blocks, it has arity 2. Similarly, above has arity 2. The stack predicate has arity 3. Predicates clear and table each have arity 1.
Given this vocabulary, we can describe the scene in Figure 2 by writing sentences that state which relations hold of which objects or groups of objects. Let's start with on. The following sentences tell us directly for each ground relational sentence whether it is true or false.
There are four above facts. The above relation holds of the same pairs of blocks as the on relation, but it includes one additional fact for block a and block c.
| above(a,b) |
| above(b,c) |
| above(a,c) |
| above(d,e) |
In similar fashion, we can encode the stack relation and the above relation. There is just one stack here - block a on block b and block b on block c.
Finally, we can write out the facts for clear and table. Blocks a and d are clear, while blocks c and e are on the table.
| clear(a) | | table(c) |
| clear(d) | | table(e) |
As with Kinship, the relations in Blocks World are constrained in various ways. For example, it is not possible for a block to be on itself. Moreover, some of these relations are entirely determined by others. For example, given the on relation, the facts about all of the other relations are entirely determined. In a later chapter, we see how to write out definitions for such concepts and thereby avoid having to write out individual facts for such defined concepts.
2.7 Reformulation
No matter how we choose to conceptualize the world, it is important to realize that there are other conceptualizations as well. Furthermore, there need not be any correspondence between the objects, functions, and relations in one conceptualization and the objects, functions, and relations in another.
In some cases, changing one's conceptualization of the world can make it impossible to express certain kinds of knowledge. A famous example of this is the controversy in the field of physics between the view of light as a wave phenomenon and the view of light in terms of particles. Each conceptualization allowed physicists to explain different aspects of the behavior of light, but neither alone sufficed. Not until the two views were merged in modern quantum physics were the discrepancies resolved.
In other cases, changing one's conceptualization can make it more difficult to express knowledge, without necessarily making it impossible. A good example of this, once again in the field of physics, is changing one's frame of reference. Given Aristotle's geocentric view of the universe, astronomers had great difficulty explaining the motions of the moon and other planets. The data were explained (with epicycles, etc.) in the Aristotelian conceptualization, although the explanation was extremely cumbersome. The switch to a heliocentric view quickly led to a more perspicuous theory.
This raises the question of what makes one conceptualization more appropriate than another. Currently, there is no comprehensive answer to this question. However, there are a few issues that are especially noteworthy.
One such issue is the grain size of the objects associated with a
conceptualization. Choosing too small a grain can make knowledge formalization prohibitively tedious. Choosing too large a grain can make it impossible.
As an example of the former problem, consider a conceptualization of the scene in Blocks World in which the objects in the universe of discourse are the atoms composing the blocks in the picture. Each block is composed of enormously many atoms, so the universe of discourse is extremely large. Although it is, in principle, possible to describe the scene at this level of detail, it is senseless if we are interested in only the vertical relationship of the blocks made up of those atoms. Of course, for a chemist interested in the composition of blocks, the atomic view of the scene might be more appropriate, and our conceptualization in terms of blocks has too large a grain.
Indistinguishability abstraction is a form of object reformulation that deals with grain size. If several objects mentioned in a dataset satisfy all of the same conditions, under appropriate circumstances, it is possible to abstract the objects to a single object that does not distinguish the identities of the individuals. This can decrease the cost of processing queries by avoiding redundant computation in which the only difference is the identities of these objects.
Another way of reconceptualizing the world is the reification of relations as objects in the universe of discourse. The advantage of this is that it allows us to consider properties of properties.
As an example, consider a Blocks World conceptualization in which there are five blocks and three unary relations, each corresponding to a different color. This conceptualization allows us to consider the colors of blocks but not the properties of those colors.
We can remedy this deficiency by reifying various color relations as objects in their own right and by adding a relation to associate blocks with colors. Because the colors are objects in the universe of discourse, we can then add relations that characterize them; e.g. warm, cool, and so forth.
There is also the reverse of reification, viz. relationalization. Combining relationalization and reification is a common way to change from one conceptualization to another.
Note that, in this discussion, no attention has been paid to the question of whether the objects in one's conceptualization of the world really exist. We have adopted neither the standpoint of realism, which posits that the objects in one's conceptualization really exist, nor that of nominalism, which holds that one's concepts have no necessary external existence. Conceptualizations are our inventions, and their justification is based solely on their utility. This lack of commitment indicates the essential ontological promiscuity of Logic Programming: Any conceptualization of the world is accommodated, and we seek those that are useful for our purposes.
Exercises
Exercise 2.1: Consider the Sorority World introduced above. Write out a dataset describing a state in which every girl likes herself and no one else.
Exercise 2.2: Consider a variation of the Sorority World example in which we have a single binary relation, called friend. friend differs from likes in two ways. It is non-reflexive, i.e. a girl cannot be friends with herself; and it is symmetric, i.e. if one girl is a friend of a second girl, then the second girl is friends with the first. Write out a dataset describing a state that satisfies the non-reflexivity and symmetry of the friend relation and so that exactly six friend facts are true. Note that there are multiple ways in which this can be done.
Exercise 2.3: Consider a variation of the Sorority World example in which we have a single binary relation, called younger. younger differs from likes in three ways. It is non-reflexive, i.e. a girl cannot be younger than herself. It is antisymmetric, i.e. if one girl is younger than a second, then the second is not younger than the first. It is transitive, i.e. if one girl is younger than a second and the second is younger than a third, then the first is younger than the third. Write out a dataset describing a state that satisfies the reflexivity, antisymmetry, and transitivity of the younger relation and so that the maximum number of younger facts are true. Note that there are multiple ways in which this can be done.
Exercise 2.4: A person x is a sibling of a person y if and only if x is a brother or a sister of y. Write out the sibling facts corresponding to the parent facts shown below.
| parent(art,bob) |
| parent(art,bea) |
| parent(bob,cal) |
| parent(bob,cam) |
| parent(bea,coe) |
| parent(bea,cory) |
Exercise 2.5: Consider the state of the Blocks World pictured below. Write out all of the above facts that are true in this state.
Exercise 2.6: Consider a world with n symbols and a single binary predicate. How many distinct facts can be written in this language?
n, 2n, n2, 2n, nn, 2n2, 22n
Exercise 2.7: Consider a world with n symbols and a single binary predicate. How many distinct datasets are possible for this language?
n, 2n, n2, 2n, nn, 2n2, 22n
Exercise 2.8: Consider a world with n symbols and a single binary predicate; and suppose that the binary relation is functional, i.e. every symbol in the first position is paired with exactly one symbol in the second position. How many distinct datasets satisfy this restriction?
n, 2n, n2, nn, 2n, 2n2, 22n
|
